
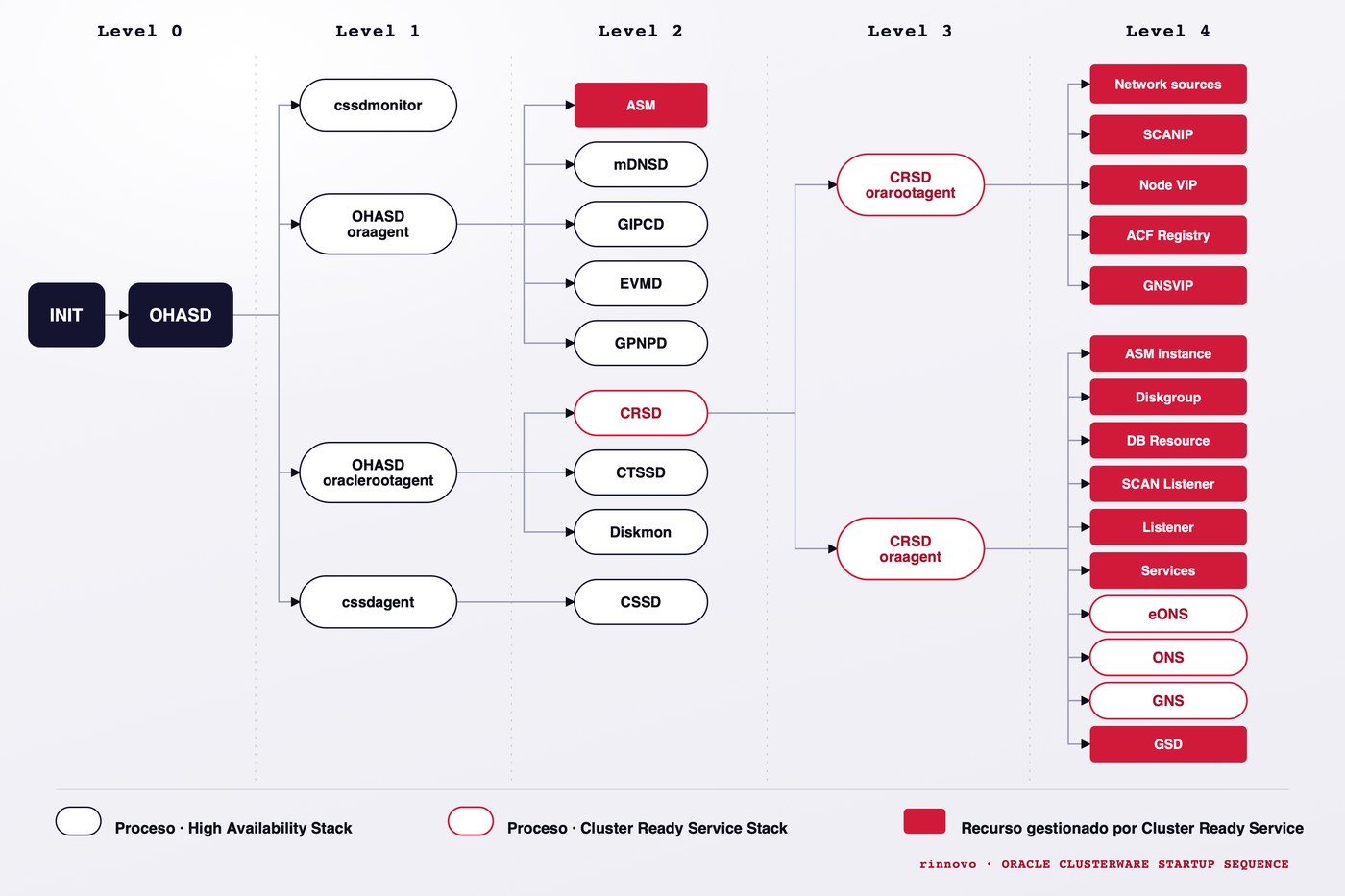
Si gestionas un clúster Oracle RAC 12c y al operar sobre los recursos del clúster aparece el error CRS-4535, hay una causa habitual y manejable detrás: el filesystem donde residen los binarios de Grid Infrastructure se llenó y el servicio CRSD dejó de comunicarse con el resto del stack.
El error
CRS-4535 · CRS-4000
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4000: Command Status failed, or completed with errorsEn paralelo, crsctl reporta que el resto del stack sí está vivo:
CRS-4638: Oracle High Availability Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is onlineLa causa
En la mayoría de casos, este escenario se origina por eventos de llenado del filesystem donde residen los binarios del Grid Infrastructure. Conviene descartar también otras causas posibles:
- Problemas de comunicación entre los nodos del RAC (red privada / interconnect).
- Problemas de permisos en el storage compartido (OCR, voting disks).
La solución
Una vez liberado el filesystem (o resuelta la causa raíz), reactiva el servicio CRSD sin reiniciar el nodo. Pasos en orden:
- Verifica que solo CRSD esté afectado y no todo el stack.
- Comprueba a nivel de sistema operativo si el proceso
crsd.binestá vivo. - Arranca el recurso
ora.crsdcon la flag-init(no reinicia el nodo). - Confirma que todos los recursos quedaron
ONLINE.
# 1 · Estado del stack — confirmar que solo CRSD está caído
./crsctl check crs
# 2 · ¿Está vivo el proceso crsd.bin?
ps -fea | grep crsd.bin
# 3 · Arrancar el recurso CRSD (sin reiniciar el nodo)
./crsctl start res ora.crsd -init
# 4 · Validar que todos los recursos quedaron ONLINE
./crsctl stat res -tResultado
Con CRSD de nuevo en línea, el clúster vuelve a coordinar la gestión de recursos (ASM, listeners, services) y los comandos crsctl dejan de devolver CRS-4535 / CRS-4000. Si el filesystem volviera a llenarse, conviene investigar la causa raíz: rotación de alert.log y trazas de CRS, auditoría, o crecimiento no controlado del diagnostic dest.